BeyondWords
Ein physikalisch modelliertes Vocal-Synthese-Plugin ohne Sample-Playback. Stimme als Instrument mit präziser Kontrolle über Glottis, Vokaltrakt und Ausdruck.
Interface-Überblick
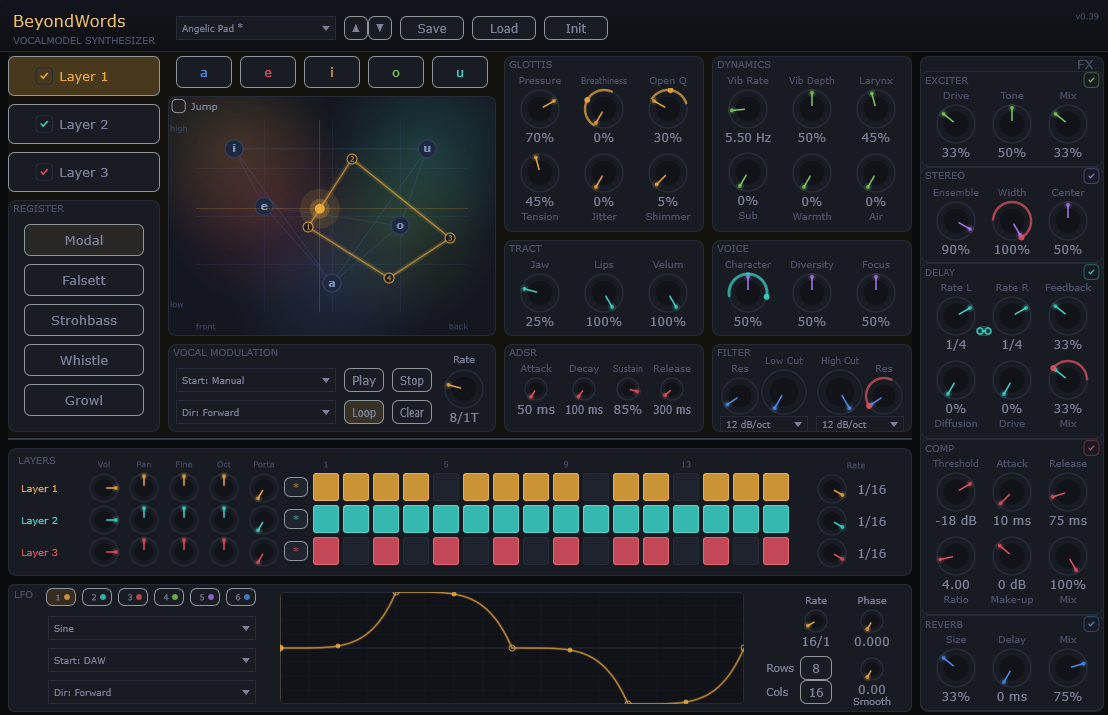

Bis zu drei unabhängige Layer laufen parallel. Jedes Register definiert einen eigenen physikalischen Stimmbereich: Modal, Falsett, Strohbass, plus Whistle und Growl für Spezialklänge.
Ein farbcodierter Step-Sequencer steuert die vokale Artikulation rhythmisch. Jede Zeile steht für eine Artikulationsdimension. Er synchronisiert mit dem DAW-Transport (Play/Stop), unterstützt Looping und flexible Rate/Subdivision.
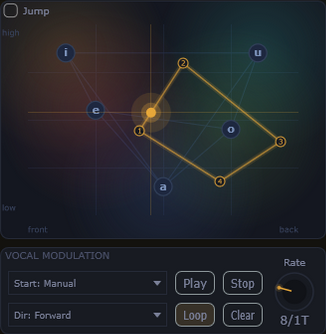
Der visuelle Vokalraum zeigt Vokalpositionen (a, e, i, u, o) als Punkte im Formantenraum. Eine editierbare Trajektorie steuert den Artikulationsverlauf für flüssige Übergänge und expressive Phrasen.
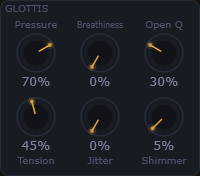
Modelliert das Verhalten der Stimmlippen physikalisch. Pressure und Open Q formen die Schwingung, Breathiness steuert den Rauschanteil, Jitter und Shimmer erzeugen natürliche Unregelmäßigkeiten.

Steuert Vibrato-Rate, Tiefe und Larynx-Position. Die Larynx-Kontrolle beeinflusst die Resonanz des gesamten Vokaltrakts und ist zentral für ausdrucksstarke Klangformung.
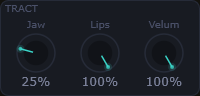
Jaw, Lips und Velum steuern die Traktform in Echtzeit. Zusammen mit dem Vokaldiagramm entsteht ein vollständiges Artikulationsmodell.
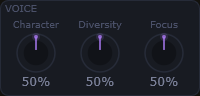
Character verschiebt die Klangfarbe von hell nach dunkel, Diversity verändert die Spektralverteilung, Focus bündelt oder streut das Klangbild.
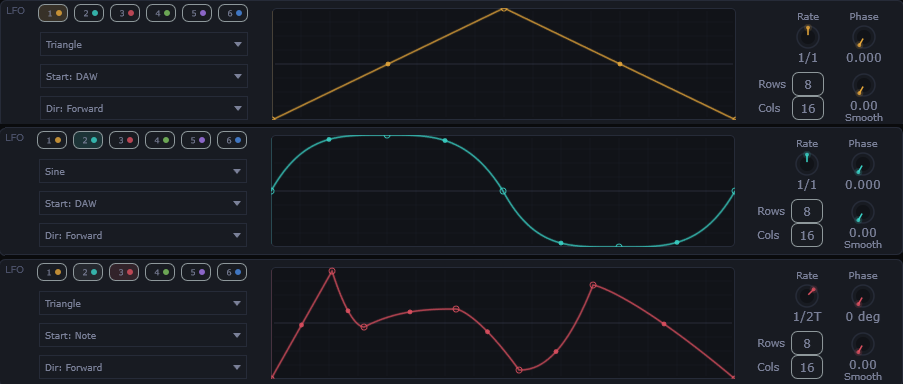
Jeder Layer hat einen eigenen LFO mit Parametern für Volume, Panning, Fine Tuning und Octave. Die Hüllkurvenansicht zeigt den Modulationsverlauf auf einen Blick.
Eine klassische ADSR-Hüllkurve formt die Lautstärke jeder Note. Der parametrische Filter mit Low-Cut, High-Cut und Resonanz erweitert die Klangformung.
Features
Spezifikationen
Systemanforderungen
Sei vor dem Launch dabei
BeyondWords ist noch in Entwicklung. Trag dich ein und erhalte Updates per Mail.
Updates erhalten